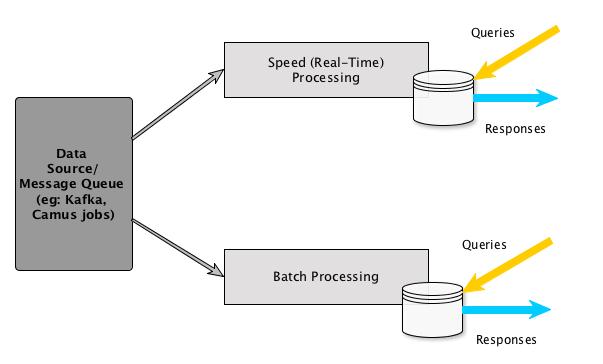
Lambda Architecture(LA) is a well-known data processing architecture designed to handle massive amount of data and it’s commonly known as Big Data. It contains both batch and stream processing methods.
When I started my journey in Data Science to process massive data came across an excellent book,

“Big Data Principles and best practices of scalable real-time data systems by Nathan Marz and James Warren.”
I recommend to read this book for all Big Data/Data Science developers.
In Big Data/Data Science project LA aims to satisfy the need to scale up and shrink indecently and also the system that is fault tolerant. Therefore, it is essential to get a correct structure for your project before starting over the implementation.
I spent almost couple of years building Lambda Architecture design for client specific projects. I realized in Big Data domain starter-kit projects are lacking when comparing to JavaScript world. So, I have published minimal skeleton project to process Big Data,

Introducing: ETL-Starter-Kit
Since the repository is to keep only the structure; different type of many sample jobs are not implemented. Based on your requirement be free to modify and implement different type of batch/streaming jobs (Spark, Hive, Pig etc)