Data engineering field is evolving and transforming in many ways, driven by the increasing amount of data being generated and the need to MAKE SENSE of it. In data engineering there are two concepts ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) that are used to move between two systems. ETL is a traditional approach and ELT is a more modern approach with the influence on the cloud platform where the data is first extracted from the source system and loaded into the target system and then transformed.

In the ELT approach, data extraction is always a challenging part for data engineers. Data extraction refers to the process of retrieving specific information from a large or small dataset. It can be done manually or through the use of various tools and techniques.
Sqoop is one of the important tools that is used across the industries. I was one of the biggest fans with Sqoop and it has helped me throughout many years to extract data from relational databases. Still we are relying on Sqoop in most of the legacy platforms.
In this journey Sqoop was not the right tool for us and currently it’s been retired by the apache community as well.
So I had to look for a better tool to extract data from multiple sources and found a lot of proprietary tools where we need to pay a lot of money. But after a while staying in this field we always pop up with crazy ideas. One of them was to create a self service ELT tool to support our data platform.

After a couple of months, we managed to build a lightweight EXTRACTOR<>LOADER tool that will support any type of database. The outcome of the product was great and the performance of EXTRACTOR-LOADER is really impressive.
The concept we relied from the old school books theories and improvised a bit to create the lightweight library. Actually you can build it using any programming language that you prefer and we mostly relied on python.
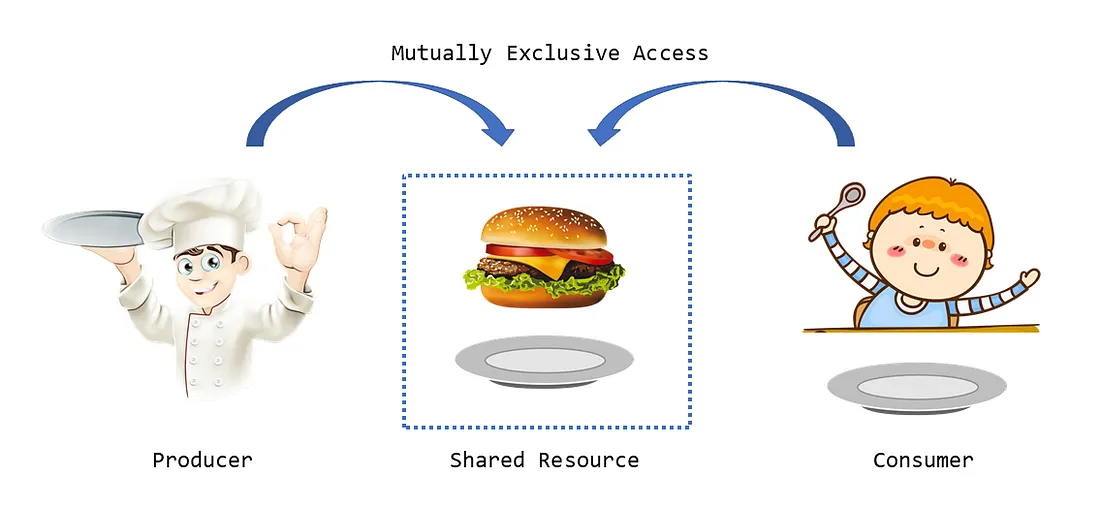
This idea got triggered from the very old theory of producer-consumer concept. Like shown in the above figure where the cook will keep preparing the food and place it on a shared resource plate and the kid keeps enjoying the food.
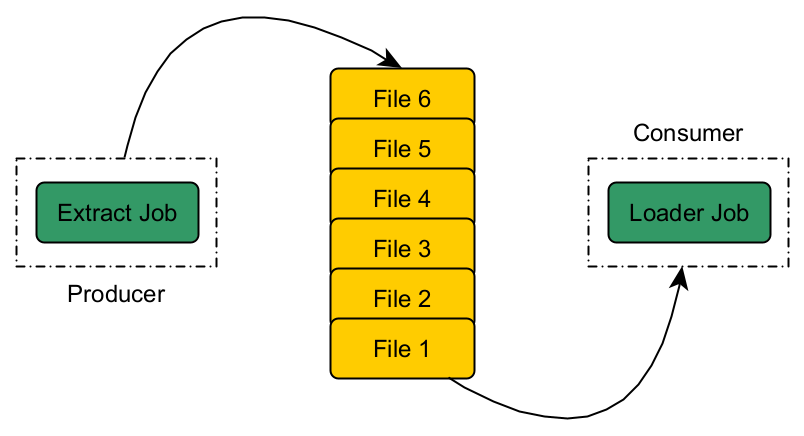
Similarly, to our EXTRACTOR LOADER problem we can apply the producer-consumer approach. Extractor job will be the producer who extracts the data from source and consumer will be a loader job that keeps consuming (loading the data) the extracted data when it’s available in the shared resource.

Currently with one producer and consumer the LIGHT-WEIGHT library; it’s showing massive improvement in the performance. Our next step will be to improve the framework to implement a multi producer-consumer solution to increase the performance of EXTRACT LOADER tasks. If we manage to crack the solution I will share the concept in my blog.
Stay Tuned!… Cheers! 🍺