The Apache Hadoop project is open-source software for reliable, scalable, distributed computing. It has revolutionized big data processing. Hadoop provides the users to store and process huge amounts of data at very low costs.
Hadoop MapReduce is used to process vast amounts of data in parallel on large clusters to manipulate these data on Hadoop in a fault-tolerant manner.
“Big data is not about the data” – Gary King
Spark is an open source alternative to MapReduce designed to make it easier to build and run fast data manipulation on Hadoop. Spark comes with a library of machine learning (ML) and graph algorithms, and also supports real-time streaming and SQL apps, via Spark Streaming and Shark, respectively. Spark exposes the Spark programming model to Java, Scala, or Python.
Spark 10 to 100 times faster than equivalent MapReduce.
The following video tutorial helped me to successfully build Spark on Mac OS.
Hope it will help you all too ☺
To start the PySpark shell, after successfully building spark (It will take some time), in the spark root folder we can see a bin folder. Run the following command in your terminal to open the shell (Figure 1).
./bin/pyspark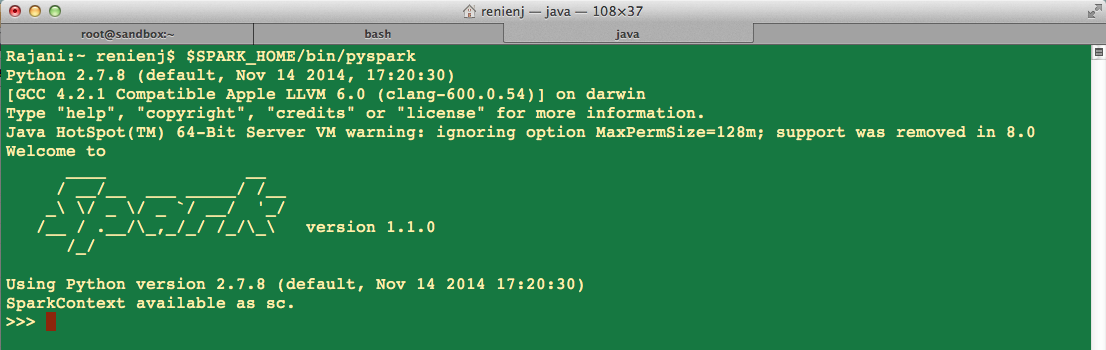
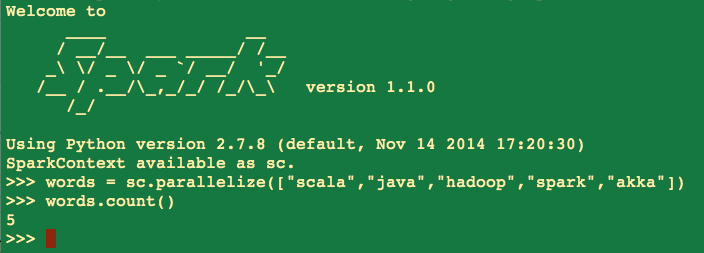
To test Spark installation run the following python code (Figure 2)
words = sc.parallelize(["scala","java","hadoop","spark","akka"])
words.count()